- ITソリューショントップ
-
製品・ソリューション
-
ダイキンのIT
 製造業向けITソリューション
製造業向けITソリューション 品質DX支援 QX digital solution
品質DX支援 QX digital solution 建設業務改善ソリューション
建設業務改善ソリューション ビル管理業務支援 DK-CONNECT BM
ビル管理業務支援 DK-CONNECT BM FILDER SiX TOP
FILDER SiX TOP FILDER SiX 電気 TOP
FILDER SiX 電気 TOP Rebro D TOP
Rebro D TOP 実験記録をデータベース化 ParsleyLab
実験記録をデータベース化 ParsleyLab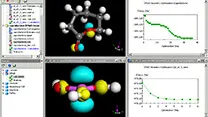 マテリアルサイエンス向けソフト Materials Studio
マテリアルサイエンス向けソフト Materials Studio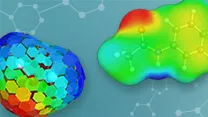 熱力学物性予測ソフトウェア COSMO
熱力学物性予測ソフトウェア COSMO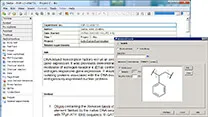 電子実験ノート
電子実験ノート 総合3DCG 制作ソフトウェア Maya
総合3DCG 制作ソフトウェア Maya 総合3DCG 制作ソフトウェア 3ds Max
総合3DCG 制作ソフトウェア 3ds Max 3Dキャラクタアニメーション制作ソフトウェア MotionBuilder
3Dキャラクタアニメーション制作ソフトウェア MotionBuilder モーションキャプチャーシステム Xsens MVN
モーションキャプチャーシステム Xsens MVN
データ・サイエンス・ソリューション
Pipeline Pilot
データサイエンスのための統合プラットフォーム
Pipeline Pilotはデータを高速に処理できる非常に優れたデータサイエンスプラットフォームです。テキスト、画像、分子構造、データベース等のデータを集約し、機械学習や統計解析を活用することで自社の様々なデータを有効活用するための強力な基盤になります。

Pipeline Pilotは、プログラミング・スキルに関係なく、多様なデータ処理をすばやく実現できます。各種の処理はパーツ(コンポーネント)で提供され、自由に変更もでき、そのパーツを組み合わせて独自の解析も行なえます。たとえば、実験データベースからのデータ収集、機械学習による予測モデル作成、そのモデルを組織内で展開運用するという一連の作業を自動化するための機能を多数備えています。
学習モデルの管理運用
ニューラルネットや勾配ブースティング(GBDT)などの高性能な学習手法の普及にともない、業務としての運用に耐えるプラットフォームの重要性はますます高まっています。Pipeline Pilotは長年にわたってアップデートを繰り返し、堅牢さと使いやすさを両立しています。たとえば勾配ブースティングによる機械学習モデルを本番サーバへデプロイするということも、コンポーネントのドラッグ&ドロップで簡潔に行うことが可能です。
マテリアルズ・インフォマティクス
材料開発の領域でもデータサイエンスの導入が進んでいます。マテリアルズ・インフォマティクスでは、人間の発想を超えた発見を狙うためや、または原料が実験値に及ぼす複雑な挙動を追うために、シミュレーションで生成した数億以上のデータを扱うことも珍しくありません。そのためには単に最新のシミュレーションができることに加えて、データベースやジョブ管理システムとの連携が必須となります。Pipeline Pilotをプラットフォームとして利用することにより、ゼロからこれらのシステムを構築した場合の維持管理コストや多大な社内の研究者の時間を節約できます。
Webサービス、Python, R連携
Pipeline Pilotで作成されたアプリケーションはWebブラウザ経由で実行することも、RESTful APIとして外部アプリケーションから呼び出すことも可能です。またPipeline PilotではPythonやRとの連携機能も備えています。たとえば社内のデータサイエンティストが作成したPythonプログラムをプロトコル化し、Webサービスとして公開すれば、組織内でベストプラクティスを素早く展開することが可能です。
このようなアプリケーションをすばやく作成可能
- データ処理
- データやアプリケーションの統合
- 分析、機械学習、ダッシュボード
- Webサービスの作成と展開
特長
- ノンプログラミングで、3000個のパーツ(コンポーネント)を組み合わせて利用できます。
- 独自のパーツ(コンポーネント)を開発し、組み込むことが可能です。
- 自社で分散しているDB、ファイルを、統合する必要なく、処理可能です。
個人が持っているデータのフォーマットを合わせて、データを統合する作業が不要、利用者がそのデータ個別に、パーツ(コンポーネント)を作成し、取り込ができます。
このような用途にご活用いただけます
- 各種シミュレーション、データベース、ジョブ投入システム連携
- 機械学習モデルの作成、運用、共有
- 自社で分散しているデータベースを一括で読み込み、検索、統合
- Webを検索し、論文、特許のデータを抽出
- 各種アプリケーションの接続、結果の抽出、統計処理、保存
お気軽にお問い合わせください
 電話でお問い合わせ
電話でお問い合わせ
- 東京(担当:SATグループ)
- 03-3520-3082
受付時間 9:00-17:30(土・日・祝除く)